Lately, consultancies with little QlikView experience have asked me to review the feasibility of using QlikView for a variety of projects. It was obvious after only a quick glance of the projects’ goals that they did not take into consideration the strengths and necessities of QlikView. I had come to believe people understood the concept of data discovery and that we were past the idea that QlikView was a just a quick reporting tool, but I was mistaken.
Many still believe QlikView only stands for fast implementation time, ease of use and a visual display. They try to adapt what they understand of BI to what they’ve heard about QlikView. Of course, you can’t blame them because we humans naturally interpret new information based on past experiences.
So, I’ve decided to write a series of blog posts that explain the strengths of QlikView so that we can understand how to use it effectively in our organizations. I will then conclude the series by detailing the reasons why QlikView projects sometimes go awry. We’ll add an extra part in each post about how Qlik Sense may or may not change how we use QlikView.
First, let’s explain the concept of data discovery and how we should go about implementing data discovery projects.
Data Discovery
Data discovery is
learning something new as a result of an active interaction with data.
Yet data discovery is only a part of the story because you can perfectly communicate a discovery with a static story, report or infographic. The tools that help us perform data exploration that results in discovery are the real innovation behind data discovery. These data exploration tools focus more on the interaction between people and data, rather the production of static reports, imitation car dashboards and flashing stoplights.
Data exploration and discovery is not new. How many of us have used SQL queries or excel to look for answers to our questions? I’m not referring to SQL stored procedures or monthly excel reports; but rather, when we use these tools to resolve new questions we have never answered before. Sometimes this process of searching for the answer lasts days, but we now have a set of Data Discovery tools available that make data exploration and discovery easier.
In comparison with previous Business Intelligence tools, these tools have made data exploration and discovery easier in the following ways.
- Agile implementation
- Easier data integration and modeling
- Real-time analysis
- Data visualization
- Data navigation
- Usability
Agile implementation
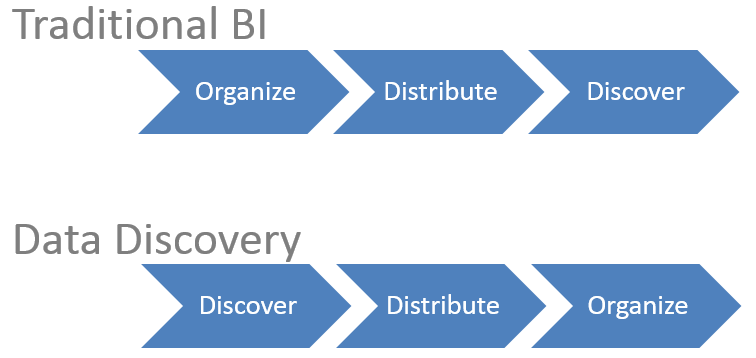
Traditional business intelligence tend to first focus on organizing, cleaning and defining data before distributing well-defined reports or cubes that allow for limited data exploration and discovery.
Data discovery tools can start the exploration and discovery process before any other activity. Ideally in a cross-functional discovery team made up of business users, data owners and QlikView developers (these three profiles can be one person), we first go through the discovery process and then distribute the results of the discovery. Only if we see it necessary to continue to develop on top of that first discovery, do we start organizing our application into a more mature solution.
This type of implementation is especially useful when the project, data and/or user requirements are not well-defined. If these three factors are well-defined, we can also implement data discovery tools in the same fashion we do traditional business intelligence. However, my experience tells me that most projects are not well-defined even when they claim to be so.
Lean Mean Qlikview
For years I suffered in my attempt to implement the first methodology QlikTech proposed called QlikView SAFE Methodology. It was a five-phase PMI-inspired methodology and did not take advantage of QlikView’s agility.

The Define stage involved us preparing a timeline of activities, estimating risks, assigning responsibilities among other items deemed important. Then the Prepare stage had us documenting as much as possible about the tables and the fields of all the data sources and then documenting what the users say they wanted. We would then start development, and once we would almost finish our application, then all hell would break loose and no change control document could save us.
After a few days we would abandon all change documentation because QlikView was so easy to adjust as we worked closely with the user, and it was the constant work in close communication with the user that finally helped us close the project. In the end, it would take 4 weeks to finish 90% of the project and 4 more weeks to finish the other 10%.

QlikTech has since proposed another project methodology called QPM that embeds agile development in what is otherwise still a PMI-inspired methodology, but again, in my opinion this methodology is overkill for most customers and still takes too much away from QlikView as an agile software.
Earlier this year when I read The Lean Startup, I finally found a methodology that closely resembled my own experience implementing QlikView. In QlikView, we almost always start with a Seeing is Believing (SiB) event that results in the creation of a rudimentary application built using real data after more or less three days. We then measure the user’s reaction to this minimal viable product (MVP), learn from their feedback, and develop according to what we’ve learned from the user.
This loop is continuous as we constantly add more features to our QlikView application. Finally, this methodology fits well when the QlikView developer has to propose a solution because the users don’t know exactly what they want or what QlikView offers them.
In other projects that are more formal, an agile methodology called Scrum is perfect. The SiB can be treated as a first sprint and used to measure the velocity to complete the rest of the project. Documentation is minimal and a constant change to the product’s requirements is expected. I recently became a Certified Scrum Master (CSM), and I recommend it to anybody that develops QlikView.

Regardless of the methodology, there are tools available to help you implement the one you choose. These tools aren’t as complicated or expensive as MS Project and more formal than Excel. I use Jira Agile because it not only helps QlikView teams that use Scrum, but also allows leaner QlikView teams to use Kanban. You can try it for free and it doesn’t cost much for the first 10 users.

Other software like BugHerd can also be used to track the progress of issues, and if you go to the Masters Summit, Rob Wunderlich can show you the BugHerd extension he’s created for QlikView.
Qlik Sense and QlikView Expressor
Qlik Sense makes it easier for business users do create their own analysis so more responsibility will fall on the business to create their own visualizations. Time spent by the business user explaining how they want their UI to look should be saved along with the time spent coordinating the UI development of a single app among various business users. The cross-functional discovery team will still be necessary to develop the data model, the library of metrics, and if necessary, a few custom extensions for the business users.
Some years ago Qlik started offering a product called QlikView Expressor that helps companies organize and govern data that is then imported into QlikView. This new product was the result of the acquisition of another company and there’s uncertainty if and how it will be fully integrated with QlikView or Qlik Sense. Yet I would imagine that they will integrate it in such a way that does not hinder the same rapid exploration and discovery that QlikView offers today.
In conclusion, the benefits that QlikView provide us as a data exploration and discovery tool is singular. We shouldn’t ruin it by using a traditional PMI-inspired methodology. We should adopt a project methodology 100% agile that plays to its strengths.
See you around,
Karl

Leave a comment